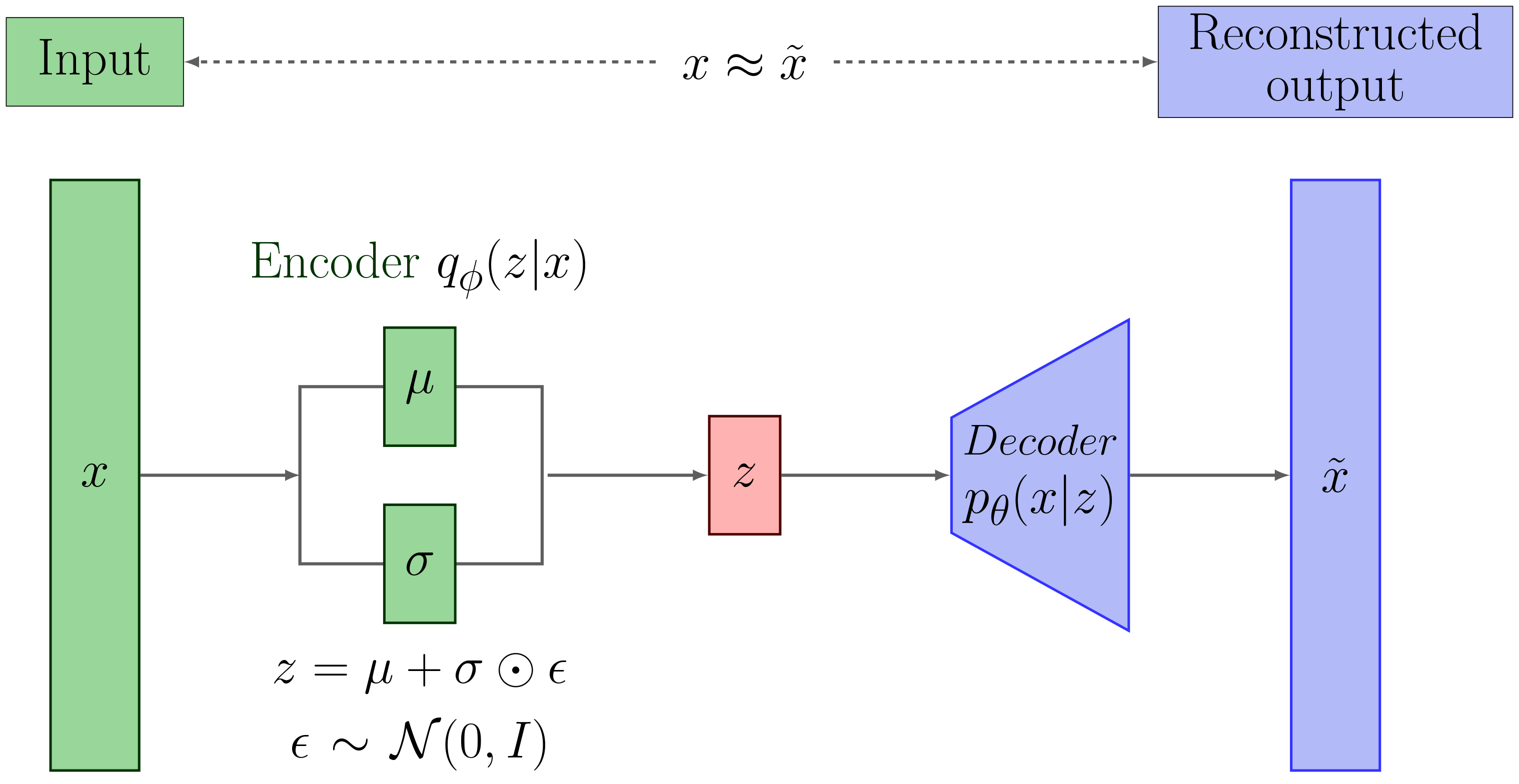
In this blog, I would like to record the basic principle behind VAE. In fact, VAE possess an encoder decoder framework, in which we can use different network structures, including DNN, CNN, etc. We can observe the framework in the following figure.
The goal of VAE
Suppose we have a distribution , and we have many samples . What we want to do is to construct a probabilistic surrogate . While generally this task can be quite difficult, we don’t have additional information of the latent variable nor do we know the explicit form of . Thus, what we can do is just to optimize
This process can be quite difficult since we don’t know anything about . However, we can assume that is related to some latent variable , where . By assuming the distribution of , i.e., the prior distribution , we can calculate the through the marginal distribution as
However, this integral is high dimensional typically and it is very difficult to compute since the we need to sample enough prior samples from to approximate the integral. However, when the latent dimension is also very high, the calculation can be untractable since the prior space is two large. However, if we can know the posterior distribution , which can decrease the search space, then the calculation of the integral can be much easier. Generally, we can write the posterior distribution as
This again needs a lot of samples from the prior samples. The solution is to parametrize the posterior distribution using an encoder and then directly sample from it to calculate the maximum likelihood, that is
Thus, we can just maximum the ELBO to get the optimal parameters. The ELBO can be further simplified as
The next question is how to calculate the loss and also the gradient with respect to the parameters. Note that the KL divergence between two Gaussian distribution can be calculated analytically as
Then by assuming the encoder is also a Gaussian distribution with mean and covariance , the first term of ELBO can be calculated as
where is the dimension of the latent variable. To calculate the second term, we need to sample from , this operation involves the following trick.
Reparameterization trick
To calculate the integral and also calculate the gradient with respect to network parameters, we need to use a raprameterization trick to generate samples from , that is
By drawing samples from , the second term of ELBO can also be calculated using Monte Carlo approximation as
If we also assume that is a Gaussian, then this part can be calculated as
Loss function
By combining the derivations in the last section, we can calculate the loss funciton as
Typically, is enough to approximate the integral, then we have the final simplified version as
To further simplify the loss function, if we assume , then the loss function can be written as